🏟️ DEBATE
A Large-Scale Benchmark for Evaluating Opinion Dynamics in Role-Playing LLM Agents
Yun-Shiuan Chuang, Ruixuan Tu, Chengtao Dai, Smit Vasani, You Li, Binwei Yao, Michael Henry Tessler,
Sijia Yang, Dhavan V. Shah, Robert D. Hawkins, Junjie Hu, Timothy T. Rogers
Sijia Yang, Dhavan V. Shah, Robert D. Hawkins, Junjie Hu, Timothy T. Rogers
Keywords:
Role-playing LLM agent
Social simulation benchmark
Multi-agent LLM system
Opinion dynamics
About
🚀TL;DR
We introduce DEBATE, a large-scale benchmark for evaluating how well role-playing LLM agents simulate realistic human opinion dynamics in multi-agent conversations.
✨Abstract
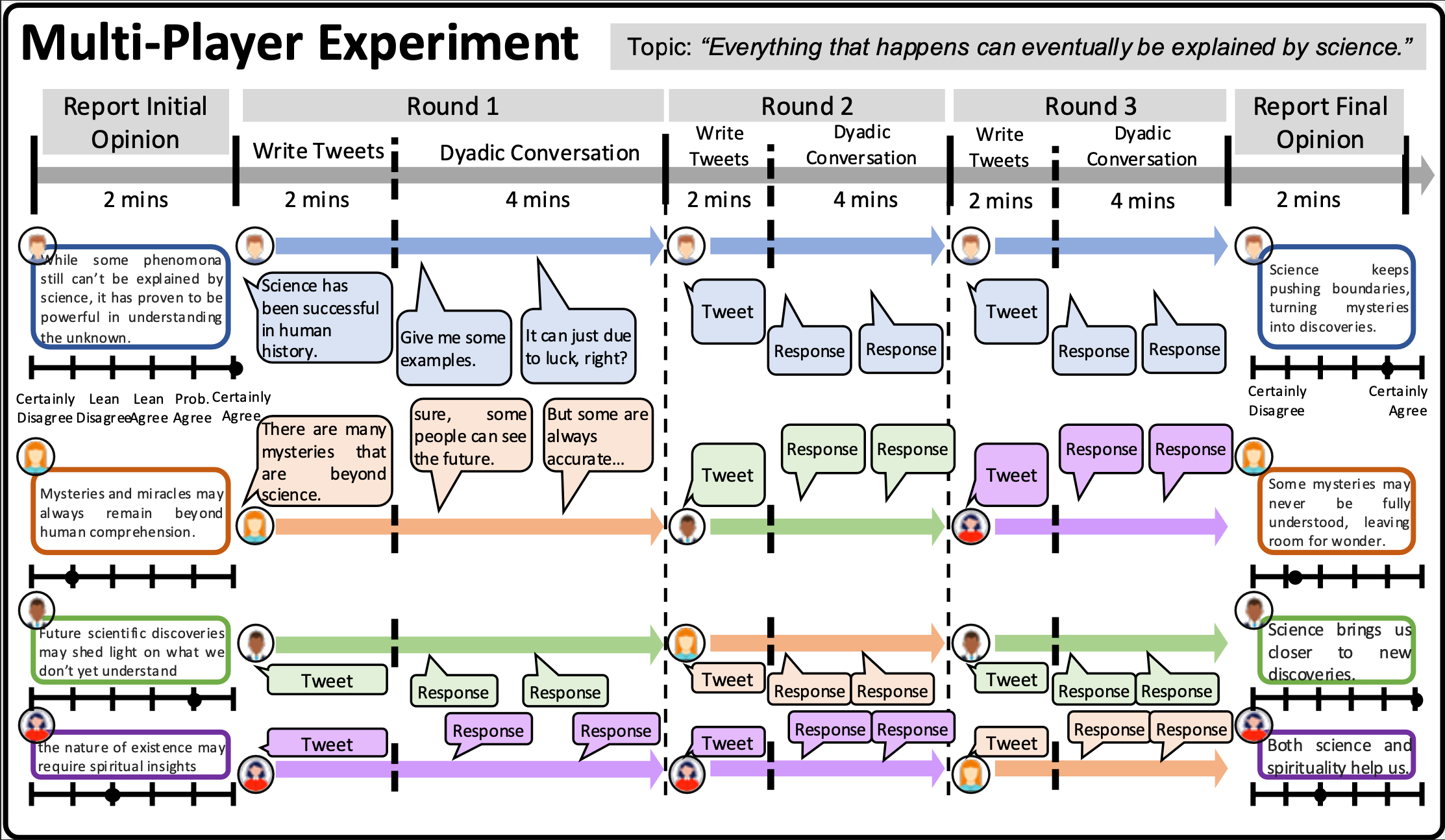
Accurately modeling opinion change through social interactions is crucial for understanding and mitigating polarization, misinformation, and societal conflict. Recent work simulates opinion dynamics with role-playing LLM agents (RPLAs), but multi-agent simulations often display unnatural group behavior (e.g., premature convergence) and lack empirical benchmarks for assessing alignment with real human group interactions.
We introduce DEBATE, a large-scale benchmark for evaluating the authenticity of opinion dynamics in multi-agent RPLA simulations. DEBATE contains 30,707 messages from 2,832 U.S.-based participants across 708 groups and 107 topics, with both public messages and private Likert-scale beliefs, enabling evaluation at the utterance and group levels (and supporting future individual-level analyses). We instantiate “digital twin” RPLAs with seven LLMs and evaluate across two settings: next-message prediction and full conversation rollout, using stance-alignment and opinion-convergence metrics. In zero-shot settings, RPLA groups exhibit strong opinion convergence relative to human groups. Post-training via supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) improves stance alignment and brings group-level convergence closer to human behavior, though discrepancies in opinion change and belief updating remain. DEBATE enables rigorous benchmarking of simulated opinion dynamics and supports future research on aligning multi-agent RPLAs with realistic human interactions. The dataset and codebase will be publicly released.
Citation
@misc{chuang2026debatelargescalebenchmarkevaluating,
title={DEBATE: A Large-Scale Benchmark for Evaluating Opinion Dynamics in Role-Playing LLM Agents},
author={Yun-Shiuan Chuang and Ruixuan Tu and Chengtao Dai and Smit Vasani and You Li and Binwei Yao and Michael Henry Tessler and Sijia Yang and Dhavan Shah and Robert Hawkins and Junjie Hu and Timothy T. Rogers},
year={2026},
eprint={2510.25110},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2510.25110},
}